Kubernetes是一个分布式系统,它有多个组件分布在网络上的不同服务器上。这些服务器可以是虚拟机或裸机服务器,称之为 Kubernetes 集群。
Kubernetes优势
Kubernetes的优势在于其自动化能力、弹性和高可用性,同时还能提供强大的扩展性和平台无关性。无论是小规模的开发环境还是大规模的生产集群,Kubernetes都能够高效管理容器化应用,帮助企业实现更快的部署周期、更稳定的服务和更高效的资源利用。具体讲述:
(1)自动化容器编排与调度:
Kubernetes自动化了容器的调度和管理工作。它根据集群中各节点的资源利用率、负载情况和策略(如优先级、亲和性等),自动选择最佳节点来部署应用容器。这减少了手动操作和人为错误,使资源使用更高效。
(2)故障自动恢复:
Kubernetes具有自愈功能,能够在应用实例出现故障时,自动重启或替换有问题的Pod,确保服务的持续可用性。
节点崩溃时,Kubernetes会重新调度相关的Pod到健康的节点上。
Pod故障时,会自动重启或替换。
如果应用健康检查失败,它还会根据预定义规则启动修复操作。
(3)可扩展性与弹性:
Kubernetes支持水平扩展,即根据应用的负载情况自动扩展或缩减Pod的数量。当应用流量增加时,Kubernetes可以根据指标(如CPU和内存使用率)自动扩容Pod实例;当负载减少时,则自动缩容,从而提高资源利用率,节省成本。
(5)服务发现与负载均衡:
Kubernetes提供了内置的服务发现和负载均衡功能。每个Pod在启动时都会被分配一个独立的IP地址,Kubernetes可以通过Service资源提供稳定的访问入口。即使Pod的IP地址发生变化,服务的访问地址也不会变动。
(6)跨平台和云无关性
Kubernetes支持在各种环境中运行,包括本地数据中心、私有云、公有云以及混合云架构。它可以让开发者和运维人员将应用无缝迁移到不同的平台上,减少对单一云平台的依赖,提供更大的灵活性。
(7)存储编排
Kubernetes可以自动挂载各种类型的存储,包括本地存储、网络文件系统、云存储等。它支持动态和静态持久化存储卷的管理,解决了容器中持久数据存储的问题。
这种存储编排功能使得Kubernetes在处理有状态应用(如数据库、缓存系统)时,也能高效管理存储资源。
Kubernetes架构
Kubernetes的架构设计是为了提供一个高度自动化、可扩展和可管理的容器编排平台。它通过控制平面管理集群的全局状态,并通过工作节点执行具体的应用部署。各个组件协同工作,使得Kubernetes能够管理数百甚至数千个容器实例。
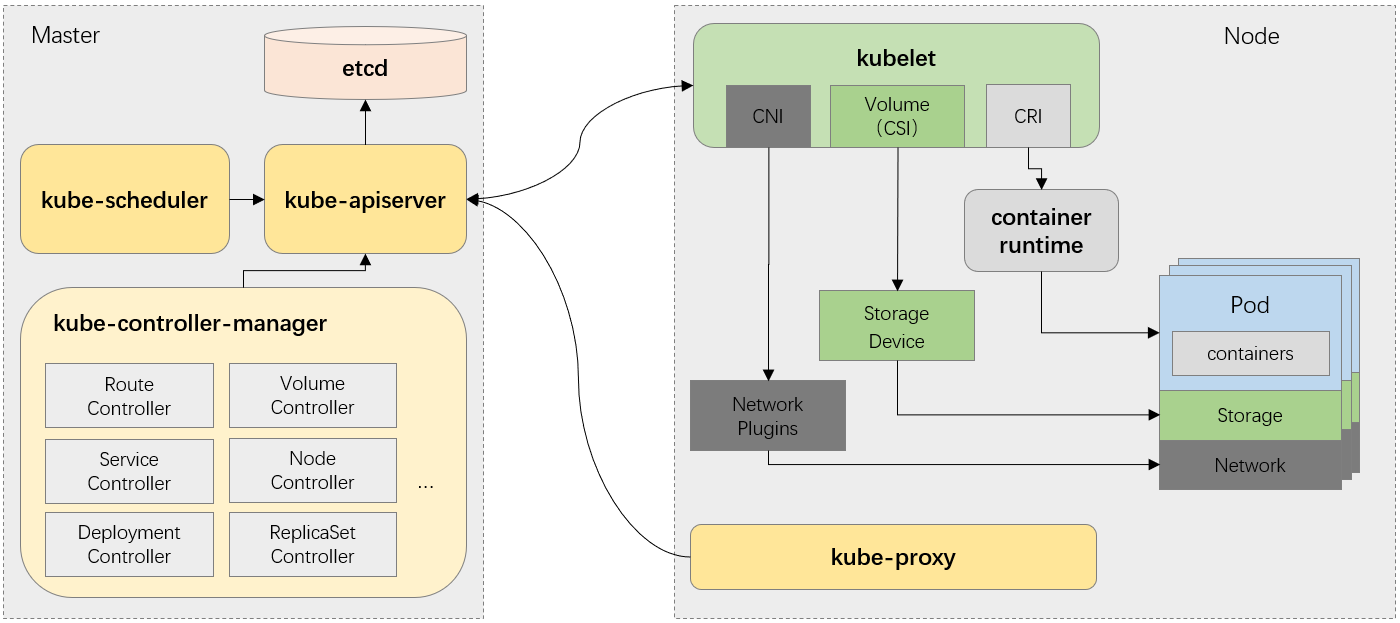
控制平面组件:
(1)API Server
作用:API Server是Kubernetes的前端接口,负责处理所有的API请求(如创建、更新、删除资源)。所有外部用户或内部组件都通过API Server与集群交互,协调控制平面和工作节点组件之间的所有进程。
功能:接收命令和配置请求(如kubectl命令),并将这些请求存储在etcd中或分发给其他组件执行,且它是唯一与etcd通信的组件。它是集群的核心入口点,提供集群的CRUD操作。
(2)etcd(分布式存储)
作用:etcd 是一个开源的强一致性分布式键值存储是Kubernetes的一致性和可靠性存储系统,用于保存整个集群的配置数据、状态和元数据。
功能:存储Kubernetes集群的所有对象状态(如Pod的定义、部署信息等)。etcd 被设计为在不牺牲一致性的情况下作为集群在多个节点上运行。作为一个分布式键值存储,确保数据的高可用性和一致性。
(3)Scheduler(调度器)
作用:调度器负责为新创建的Pod选择合适的工作节点运行。它根据集群的资源使用情况和策略进行调度(指定容器要求)。
功能:当Pod创建时,它需要被分配到某个节点。调度器会考虑节点的资源(CPU、内存)、节点标签、节点状态等因素,并决定在哪个节点上启动Pod。调度策略可以自定义,确保应用的高效分布和资源利用率。
调度原理:
调度器会持续监控集群中未被调度的 Pod,当发现一个新创建的 Pod 处于 Pending 状态时,它会开始为这个 Pod 选择一个合适的节点。Pod 的定义中通常包含了资源需求、亲和性和反亲和性等调度规则。调度器首先会根据 硬性条件 对集群中的节点进行筛选,排除不符合条件的节点。这些硬性条件包括:
节点必须有足够的 CPU、内存等资源来满足 Pod 的需求。如果 Pod 规定了要调度到特定标签的节点,调度器会筛选出带有这些标签的节点。调度器会根据这些过滤条件,将不符合要求的节点排除,最终得到一个“候选节点列表”。
过滤后,调度器会对剩下的候选节点进行评分。评分的目的是从符合条件的节点中选出“最优节点”。 在打分结束后,调度器会选择得分最高的节点作为最终的调度目标,并将 Pod 分配到该节点上。 调度结果会通过 Kubernetes API 提交给 API Server,然后该节点上的 Kubelet 会接收任务并启动对应的容器。最后,调度器通过 Kubernetes 的 bind API 将 Pod 绑定到选择的节点上。此时,Pod 的状态会从 Pending 变为 Running,并开始在该节点上启动对应的容器。
(4)Controller Manager(控制器管理器)
作用:Controller Manager是集群内多个控制器的集合,每个控制器都负责维护集群中某些资源的期望状态与实际状态一致。
ReplicationController:确保指定数量的Pod副本运行。
Node Controller:监控节点的健康状态,发现节点故障时移除不健康节点上的Pod。
Endpoint Controller:负责更新服务与Pod之间的映射关系。
Service Account & Token Controller:创建默认的账号和访问权限。
控制器负责自动化操作,如应用恢复、扩展和滚动更新
工作节点组件:
(1)Kubelet
Kubelet 也是一个控制器,运行在每个工作节点上的核心代理,负责管理该节点上所有的Pod和容器,它监视 Pod 的变化,并利用节点的容器运行时来拉取镜像、运行容器等。
功能:通过与API Server交互,接收调度的Pod信息,确保容器按照预期运行。定期向API Server汇报Pod和节点的状态。执行健康检查,确保Pod处于健康状态。
Kubelet是工作节点上与控制平面交互的主要代理,直接与容器运行时交互(如Docker或containerd)来管理容器。
(2)Kube-Proxy(代理)
Kube-proxy 是一个守护进程,它作为守护进程集在每个节点上运行。Kubernetes 中的服务是一种在内部或向外部流量公开一组 Pod 的方法。创建服务对象时,它会为其分配一个虚拟 IP,被称为 clusterIP。它只能在 Kubernetes 集群中访问。它是一个代理组件,用于实现 Pod 的 Kubernetes 服务概念。Kube 代理与 API 服务器通信,以获取有关服务 (ClusterIP) 和相应 Pod IP 和端口(端点)的详细信息。它还监视服务和终结点的更改。然后,kube-proxy 使用以下任一模式创建/更新规则,将流量路由到 Service 后面的 Pod。
功能:
维护集群内部服务的虚拟IP地址,并将流量代理到实际的Pod上。
实现服务的负载均衡,确保多个Pod实例之间的流量分发。
管理网络规则,确保Pod间通信的正确性。
Kube-Proxy实现了Kubernetes的网络模型,使得Pod之间可以跨节点通信,并为服务提供稳定的访问入口。
(3)容器运行时(Container Runtime)
作用:容器运行时是负责拉取镜像、启动和管理容器的组件。
功能:Kubelet通过与容器运行时(如Docker、containerd、CRI-O等)交互,启动和停止容器。容器运行时支持容器的创建、运行和删除等生命周期管理。
Kubernetes工作流程
用户通过指令或者YAML文件定义 Kubernetes 资源(如 Pod、Service、Deployment 等)时会通过 kubectl 命令与 API Server 交互,向集群提交资源定义。API Server 是 Kubernetes 集群的入口,负责验证和处理来自 kubectl 或其他应用的请求。API Server 处理后,将资源状态保存在 etcd 中,作为集群的配置状态。Scheduler 根据集群中可用资源、节点状态和调度策略,决定将新创建的 Pod 分配到哪个节点运行。调度器考虑 CPU、内存、拓扑等因素。调度完成后,目标节点上的 Kubelet 接收到调度的 Pod 定义,负责在节点上创建和管理 Pod。Kubelet 会调用容器运行时(如 Docker 或 containerd)启动容器。